StatEval: A Comprehensive Benchmark for Large Language Models in Statistics
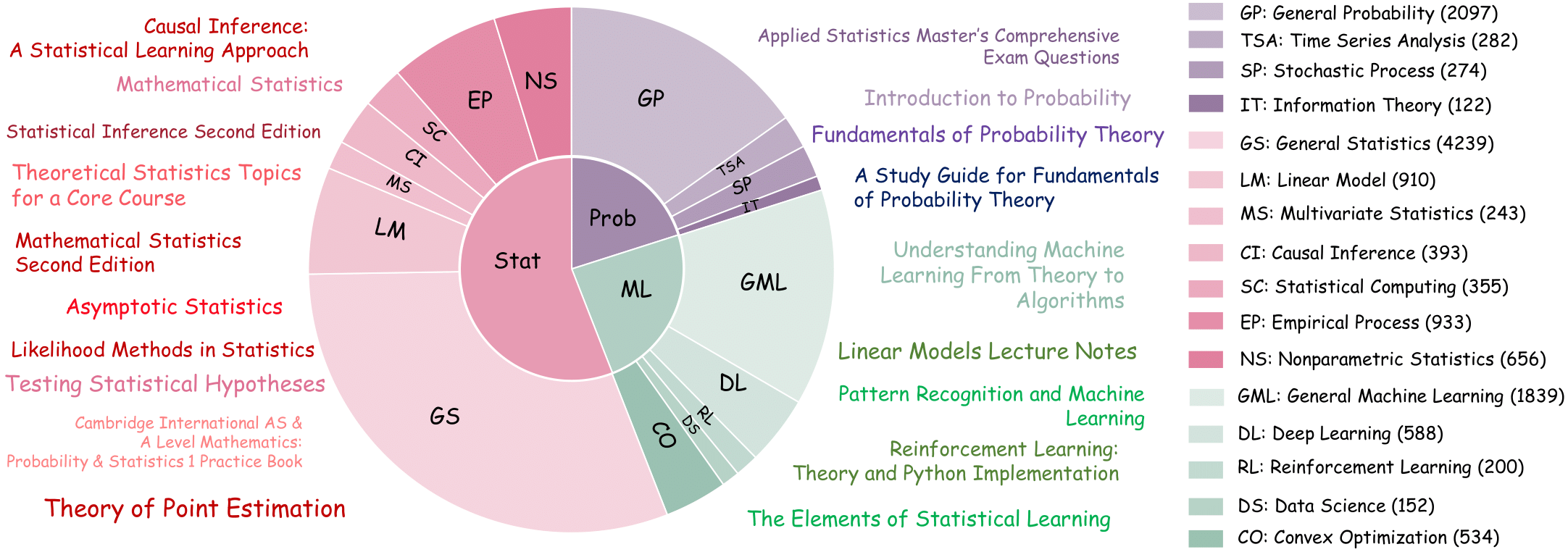
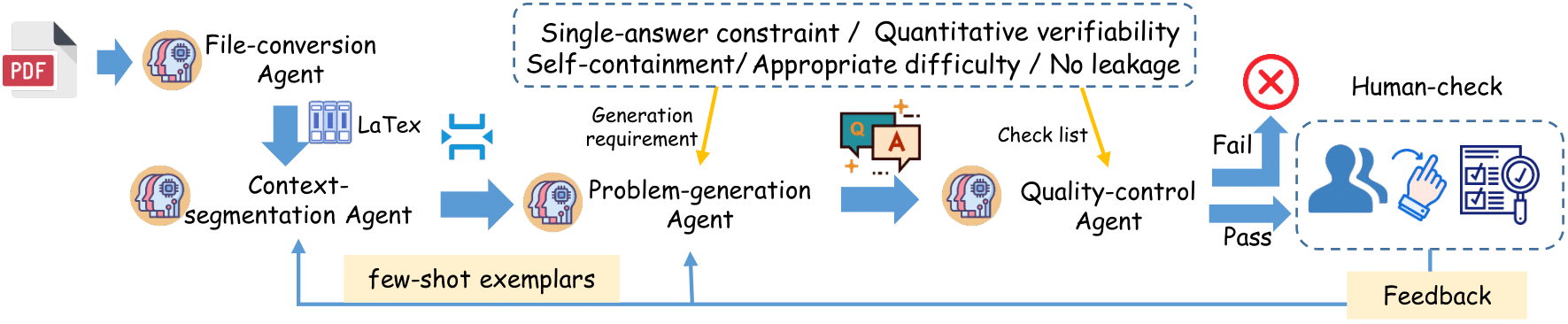
StatEval, developed by the team of Professor Fan Zhou at Shanghai University of Finance and Economics, is the first benchmark systematically organized along both difficulty and disciplinary axes to evaluate large language models’ statistical reasoning.
It includes a Foundational Knowledge Dataset of over 13,000 problems from 50+ textbooks and a Statistical Research Dataset of over 2,000 proof-based questions sourced from 18 top-tier journals in statistics, probability, econometrics, and machine learning.
The test sets of both datasets are publicly available and can be accessed on Hugging Face:
📘 Foundational Knowledge Dataset:
View on Hugging Face
📗 Statistical Research Dataset:
View on Hugging Face